
什么是贝壳?
它是用户与操作系统交互的可见部分,用户通过向shell提供命令与操作系统交互,shell反过来解释并执行这些命令。
下图显示了简化的执行过程,其中shell接收输入, 将其传递给词法分析器(将详细讨论),后者将创建标记,然后词法分析器的输出将传递给解析器,解析器将检查语法错误并执行指定的语义操作(这将构建命令表),最后,当解析器到达某个点时,表将被执行。
外壳将由3个组件实现,如下面的架构图所示:
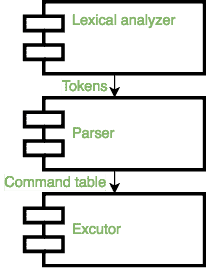
1.词法分析器 输入解析的第一部分是词法分析阶段,输入被逐字读取以形成标记,我们将使用一个名为lex的命令来构建文件,在这个文件中,我们将定义模式,后跟:标记名词法分析器将逐个字符读取输入,当模式匹配左侧的字符串时,它将转换为右侧的字符串。 前任:
Command input: ls -al
解析器将读取l,然后s,形成一个名为WORD的标记,然后读取字符(al)并形成一个选项。输出将是WORD选项,该输出将被传递给解析器,以检查是否存在语法错误。
1.#:IO 2. [ 1 ]?”>” : 木卫一 3.“:IO 5. [ 1]?”>>” : 木卫一 6.[1-2]“>&[1-2]:IOR 7.“|”:管道 8.“&”:符号和 9.[]“-”[a-zA-Z0-9]*:选项 10.[]“–”[a-zA-Z=a-zA-Z]*:选项2 11. \%=+’”()$/\_-.?*~a-zA-Z0-9]+:单词
上面的语法由11个标记组成,这些标记在输入满足标记描述时形成。 IO令牌由一个#字符或一个“>”组成,前面可以是数字1(最多一次),或者“我们将其作为一个新令牌引入,以取代错误重定向令牌,IO的另一种形式是使用“>>”,前面可以是数字1(最多一次),最后是“>&”,它是一个IOR,前面和/或后面可以是一个或两个。
pipe和ampersand标记分别在“|”和“&”处形成,选项标记在前面有一个连字符,后面有空格,后面有任何字母字符或数字时形成。 当两个连字符前面有空格,后面有任何字母字符时,就会形成option2标记。 单词标记可以由字母字符、数字和以下字符构成%、=、+、’、“、(、)、$、/、-、、?、*~
2.解析器 从输入中生成标记后,标记作为流传递给解析器,解析器解析输入以检测语法错误并执行指定的语义操作。解析器可以被认为是语言的语法和语法(它定义了我们的命令将如何看起来像可接受的东西),我们将使用一个名为yacc的命令来编译语法,我们将语法构造为一种状态形式,这使得语法的构造和部署更容易。
下面是我们的语法定义:
1.q00:NEWLINE{return 0;}|cmd q1 q0 |错误; 2.q0:NEWLINE{return 1;}|管道q00{clrcont;}; 3.q1:选项q2 |选项q2 |参数列表q3 | io |修改器q4 |背景q5 | io |描述q3 |/*空*/{InsertNode();clrcont();}; 4.q2:arg_list q3 | io_修饰符q4 | io_descr q3 |后台q5 |/*空*/{InsertNode();clrcont();}; 5.q3:io_修饰符q4 | io_descr q3 |背景q5 |/*空*/{InsertNode();clrcont();}; 6.q4:文件q3; 7.cmd:WORD{cmad.cmd=yylval.str;}; 8.arg|u列表:arg|arg|u列表; 9.arg:WORD{insertArgNode(yylval.str);}; 10.文件:WORD{io_red(yylval.str);}; 11.io_修饰语:io{cmad.op=yylval.str;}; 12.io_descr:IOR{cmad.op=yylval.str;}; 13.选项:选项{cmad.opt=yylval.str;}选项2{cmad.opt2=yylval.str;}; 14.背景:符号{bg=’1’;}; 15.q5:/*空*/{InsertNode();clrcont();};
上述语法指定了解析过程的不同状态,
解析器从状态q00开始解析,直到到达状态q5、q3、q1中的一个,由于使用的解析技术(自下而上的解析),以相反的方式发生。语法根据标记的位置减少标记,如果单词出现在开头,可以将其减少为cmd,如果它出现在命令之后,则可以将其减少为arg_list,文件如果在重定向后出现,则根据语法分析句子,从状态q00开始,解析器通过读取cmd移动到状态q1,在状态q1,如果解析器读取选项,则句子可以有以下参数之一,IO或背景在后面,或者什么都没有,如果解析器读取参数,那么句子只能在后面有重定向,如果解析器读取一个符号,那么后面应该没有任何内容。
然后,当解析器读取管道时,该过程再次开始,这允许多个简单命令通过管道连接,形成一个复杂命令。 我们将简单命令定义为包含命令、选项、参数和/或IO重定向的任何命令。 使用管道将多个简单命令组合在一起,形成一个我们称之为复杂命令的结构。
与语法相关联的语义动作构建解析表,并将命令值分配给数据结构,该数据结构在构建命令表后将发送给执行器。 命令表由简单命令行组成,这些行由管道连接的复杂命令、保存要执行的命令名的简单命令项、与命令一起执行的选项、保存应传递给命令的参数的参数组成,标准输入(stdIn)指定命令将从中获取输入的位置。默认情况下,它是终端,除非命令中另有规定。标准输出(stdOut)指定命令将打印执行输出的位置,默认情况下,它是终端,标准错误(stdError)指定命令打印执行错误消息的位置,默认情况下,除非用户重定向,否则它是终端。
构建的语法允许以下语法:

它允许带有选项、参数、IO重定向的命令作为后台进程(&)。如果我们连接多个简单命令,就形成了一个复杂的命令。
在解析命令时,解析器将命令详细信息保存在表中,以便传递给执行器。
我们选择了一个表作为数据结构,我们需要存储关于每个命令、命令、选项、选项2、参数、StdIn、StdOut、StdError的以下信息。
例如:
ls –al | sort -r
该命令将生成下表(每行都是一个简单的命令,表本身是一个复杂的命令)。

3.遗嘱执行人
在创建命令表之后,执行器负责为表中的每个命令创建一个进程,并在需要时处理任何重定向。 执行器在表中迭代执行每个简单命令,并在表中的每个条目(简单命令)将其连接到下一个命令。执行器命令将命令、选项和参数传递到execvp函数,该函数将当前调用过程替换为被调用过程,execvp函数作为第一个参数,接收要执行的文件名和一个以null结尾的数组,该数组包含后跟参数的选项(如果有的话)。
但是,在调用execvp之前,执行器在shell中处理重定向,如果命令前面有一个命令,这意味着之前有一个管道,因此命令的输入被设置为从上一个管道接收,那么将检查该命令是否存在任何输入重定向,如果存在该重定向,将覆盖来自上一个管道的输入,如果命令前面没有命令,则没有管道(简单命令),否则(多个简单命令)命令的输出将发送到表中的下一个命令,然后,如果存在输入重定向,则会检查该命令的输出重定向。来自指定文件的输入会覆盖来自上一个命令的输入。
处理重定向后,将检查命令的后台标志,该标志指示shell是否应等待命令完成执行或发送进程以在后台执行,现在为了让执行者执行命令,它必须创建要执行的shell映像,executor分叉当前进程(shell)并在这个分叉的子进程上执行命令。
执行器首先执行第一行,将命令的输出设置为标准输出,然后覆盖管道的输出,以便由第二个命令接收,在第一个命令(ls–al)执行后,第二个命令开始执行,首先分配要从标准输入读取的输入,然后,由于该命令前面有另一个命令,因此输入设置为从管道接收,并且由于该命令不包含任何输入重定向(来自文件),因此该命令的标准输入将保留在管道中,该命令的标准输出将显示在屏幕上,然后检查该命令是否应将其输出发送到以下命令,在本例中,这是最后一个命令,因此输出不会被管道覆盖,但由于该命令具有指向文件的输出重定向,该文件将覆盖标准输出。
执行以下命令
ls –al | sort –r >file
解析器构建的表如下所示:

executor代码将在这个表上迭代,执行上面提到的步骤,并在命令完成时清除所有内容,以准备接收下一个命令。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)



