
Python是进行数据分析的优秀语言,主要是因为以数据为中心的Python软件包的奇妙生态系统。 熊猫 是这些软件包中的一个,使导入和分析数据变得更加容易。 有一些重要的数学运算可以在pandas系列上执行,以简化使用Python进行的数据分析,并节省大量时间。
null
要获取使用的数据集,请单击 在这里 .
s=read_csv("stock.csv", squeeze=True)#reading csv file and making series
| 作用 | 使用 |
|---|---|
| s、 sum() | 返回序列中所有值的总和 |
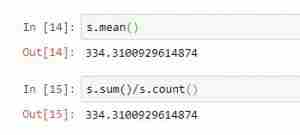
| s、 平均值() |
返回序列中所有值的平均值。等于s.sum()/s.count() |
| s、 std() | 返回所有值的标准偏差 |
| s、 最小值()或s.最大值() | 从序列中返回最小值和最大值 |
| s、 idxmin()或s.idxmax() | 返回序列中最小值或最大值的索引 |
| s、 中位数() | 返回所有值的中值 |
| s、 模式() | 返回序列的模式 |
| s、 值_计数() |
返回带有每个值频率的序列 |
| s、 描述() |
根据传递的数据类型,返回包含平均值、模式等信息的序列 |
![图片[2]-Python |用于数据分析的数学运算-yiteyi-C++库](https://www.yiteyi.com/wp-content/uploads/geeks/geeks_valuecount-300x191.jpg)
![图片[3]-Python |用于数据分析的数学运算-yiteyi-C++库](https://www.yiteyi.com/wp-content/uploads/geeks/geeks_describe-300x154.jpg)
代码#1:
Python3
# import pandas for reading csv file import pandas as pd #reading csv file s = pd.read_csv( "stock.csv" , squeeze = True ) #using count function print (s.count()) #using sum function print (s. sum ()) #using mean function print (s.mean()) #calculation average print (s. sum () / s.count()) #using std function print (s.std()) #using min function print (s. min ()) #using max function print (s. max ()) #using count function print (s.median()) #using mode function print (s.mode()) |
输出:
30121006942.0334.3100929614874334.3100929614874173.1872047711311549.95782.22283.3150 291.21
代码#2:
Python3
# import pandas for reading csv file import pandas as pd #reading csv file s = pd.read_csv( "stock.csv" , squeeze = True ) #using describe function print (s.describe()) #using count function print (s.idxmax()) #using idxmin function print (s.idxmin()) #count of elements having value 3 print (s.value_counts().head( 3 )) |
输出:
dtype: float64count 3012.000000mean 334.310093std 173.187205min 49.95000025% 218.04500050% 283.31500075% 443.000000max 782.220000Name: Stock Price, dtype: float64301111291.21 5288.47 3194.80 3Name: Stock Price, dtype: int64
意外输出和限制:
- .sum()。平均值()。模式()。中值()和其他此类数学运算不适用于字符串或除数值以外的任何其他数据类型。
- 字符串序列的.sum()将给出意外的输出,并通过串联每个字符串返回一个字符串。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)





