
我们强烈建议将下面的帖子作为这篇文章的先决条件。 散列|集1(简介) 散列|集2(单独链接)
公开寻址 与独立链接一样,开放寻址也是一种处理冲突的方法。在开放寻址中,所有元素都存储在哈希表中。因此,在任何时候,表的大小都必须大于或等于键的总数(请注意,如果需要,我们可以通过复制旧数据来增加表的大小)。
插入(k):继续探测,直到找到一个空插槽。找到空插槽后,插入k。
搜索(k):继续探测,直到插槽的键不等于k或者到达一个空插槽。
删除(k): 删除操作很有趣 .如果我们只是删除一个密钥,那么搜索可能会失败。因此,删除的密钥槽被特别标记为“已删除”。 insert可以在已删除的插槽中插入项目,但搜索不会在已删除的插槽处停止。
开放寻址通过以下方式完成:
a) 线性探测: 在线性探测中,我们线性探测下一个插槽。例如,两个探针之间的典型间隙为1,如下例所示。 允许 散列(x) 是使用哈希函数计算的插槽索引,并且 s 是桌子的尺寸吗
If slot hash(x) % S is full, then we try (hash(x) + 1) % SIf (hash(x) + 1) % S is also full, then we try (hash(x) + 2) % SIf (hash(x) + 2) % S is also full, then we try (hash(x) + 3) % S ....................................................................................................
让我们考虑一个简单的哈希函数,作为“密钥mod 7”和一个密钥序列,如50, 700, 76、85, 92, 73、101。
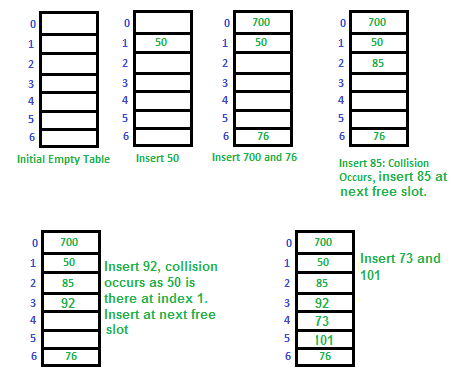
线性探测的挑战:
- 主要群集: 线性探测的一个问题是主要的聚类,许多连续的元素形成了组,并且开始花时间来寻找一个空闲的时隙或搜索一个元素。
- 二次聚类 : 二次聚类不那么严重,如果两条记录的初始位置相同,它们只有相同的碰撞链(探测序列)。
b) 二次探测 我们在找我 2. 第i次迭代中的第个插槽。
let hash(x) be the slot index computed using hash function. If slot hash(x) % S is full, then we try (hash(x) + 1*1) % SIf (hash(x) + 1*1) % S is also full, then we try (hash(x) + 2*2) % SIf (hash(x) + 2*2) % S is also full, then we try (hash(x) + 3*3) % S....................................................................................................
c) 双重散列 我们使用另一个散列函数hash2(x)并在第i个循环中查找i*hash2(x)槽。
let hash(x) be the slot index computed using hash function. If slot hash(x) % S is full, then we try (hash(x) + 1*hash2(x)) % SIf (hash(x) + 1*hash2(x)) % S is also full, then we try (hash(x) + 2*hash2(x)) % SIf (hash(x) + 2*hash2(x)) % S is also full, then we try (hash(x) + 3*hash2(x)) % S....................................................................................................
看见 这 对于分步图。
以上三种方法的比较: 线性探测具有最好的缓存性能,但会受到集群的影响。线性探测的另一个优点是易于计算。 二次探测在缓存性能和集群方面介于两者之间。 双哈希的缓存性能很差,但没有集群。由于需要计算两个哈希函数,双哈希需要更多的计算时间。
| 不。 | 分离链 | 公开寻址 |
|---|---|---|
| 1. | 链接更容易实现。 | 开放寻址需要更多的计算。 |
| 2. | 在链接中,哈希表永远不会填满,我们总是可以向链中添加更多元素。 | 在开放寻址中,表可能已满。 |
| 3. | 链接对哈希函数或加载因子不太敏感。 | 开放寻址需要格外小心,以避免集群和负载因素。 |
| 4. | 当不知道插入或删除键的数量和频率时,通常使用链接。 | 当已知键的频率和数量时,使用开放寻址。 |
| 5. | 链接的缓存性能不好,因为密钥是使用链表存储的。 | 开放寻址提供了更好的缓存性能,因为所有内容都存储在同一个表中。 |
| 6. | 浪费空间(链中哈希表的某些部分从未使用)。 | 在开放寻址中,即使输入没有映射到插槽,也可以使用插槽。 |
| 7. | 链接使用额外的链接空间。 | 开放地址中没有链接 |
公开寻址的性能: 与链接一样,可以在假设每个键都有可能被散列到表的任何插槽(简单的统一散列)的情况下评估散列的性能
m = Number of slots in the hash tablen = Number of keys to be inserted in the hash table Load factor α = n/m ( < 1 )Expected time to search/insert/delete < 1/(1 - α) So Search, Insert and Delete take (1/(1 - α)) time
参考资料: https://www.youtube.com/playlist?list=PLqM7alHXFySGwXaessYMemAnITqlZdZVE http://courses.csail.mit.edu/6.006/fall11/lectures/lecture10.pdf https://www.cse.cuhk.edu.hk/irwin.king/_media/teaching/csc2100b/tu6.pdf
如果您发现任何不正确的地方,或者您想分享有关上述主题的更多信息,请写下评论。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)



