
索引是一种优化数据库性能的方法,它可以最大限度地减少处理查询时所需的磁盘访问次数。它是一种数据结构技术,用于快速定位和访问数据库中的数据。
索引是使用几个数据库列创建的。
- 第一列是 搜索键 它包含表的主键或候选键的副本。这些值按排序顺序存储,以便快速访问相应的数据。 注:数据可能按顺序存储,也可能不按顺序存储。
- 第二列是 数据参考 或 指针 它包含一组指针,其中包含可以在其中找到特定键值的磁盘块的地址。
![图片[1]-数据库中的索引|集1-yiteyi-C++库](https://www.yiteyi.com/wp-content/uploads/geeks/20190812/geeks_Structure-of-an-Index-in-Database.jpg)
索引具有多种属性:
- 访问类型 :这是指访问类型,例如基于值的搜索、范围访问等。
- 访问时间 :指找到特定数据元素或元素集所需的时间。
- 插入时间 :指找到合适的空间并插入新数据所需的时间。
- 删除时间 :查找并删除项目以及更新索引结构所需的时间。
- 头顶空间 :指索引所需的额外空间。
通常,有两种类型的文件组织机制,然后是存储数据的索引方法:
1.顺序文件组织或顺序索引文件: 在这种情况下,索引基于值的排序。它们通常是快速的,是一种更传统的存储机制。这些有序或连续的文件组织可能以密集或稀疏的格式存储数据:
(i) 密集指数:
- 对于数据文件中的每个搜索关键字值,都有一个索引记录。
- 此记录包含搜索关键字,还包含对具有该搜索关键字值的第一条数据记录的引用。
![图片[2]-数据库中的索引|集1-yiteyi-C++库](https://www.yiteyi.com/wp-content/uploads/geeks/20190812/geeks_Dense-Index.jpg)
(ii)稀疏索引:
- 索引记录仅为数据文件中的少数项显示。每个项目显示为一个块。
- 为了定位记录,我们找到最大搜索键值小于或等于我们要查找的搜索键值的索引记录。
- 我们从索引记录指向的那条记录开始,然后继续执行文件中的指针(即顺序),直到找到所需的记录。
![图片[3]-数据库中的索引|集1-yiteyi-C++库](https://www.yiteyi.com/wp-content/uploads/geeks/20190812/geeks_Sparse-Index.jpg)
2.散列文件组织: 指数基于在一系列桶中均匀分布的值。分配值的存储桶由一个名为哈希函数的函数确定。
主要有三种索引方法:
- 聚类索引
- 非聚集索引或辅助索引
- 多级索引
1.聚类索引 当两个以上的记录存储在同一个文件中时,这些类型的存储称为集群索引。通过使用聚类索引,我们可以降低搜索成本,因为与同一事物相关的多个记录存储在一个位置,并且它还提供了两个以上表(记录)的频繁连接。 聚类索引是在有序数据文件上定义的。数据文件按非键字段排序。在某些情况下,索引是在非主键列上创建的,对于每条记录来说,这些列可能不是唯一的。在这种情况下,为了更快地识别记录,我们将两个或更多列组合在一起,以获得唯一的值,并从中创建索引。这种方法被称为聚类索引。基本上,具有相似特征的记录被分组在一起,并为这些组创建索引。 例如,每个学期学习的学生被分组在一起。i、 e.1 圣 学期学生,2 钕 学期学生,3 研发部 将学期学生等分组。
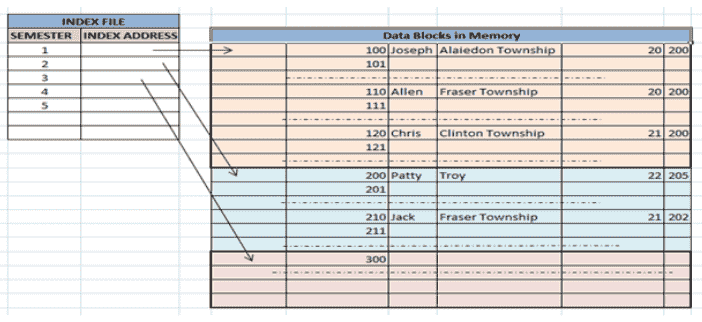
根据名字排序的聚集索引(搜索键)
主要索引: 这是一种聚集索引,其中数据根据搜索键进行排序,数据库表的主键用于创建索引。它是一种默认的索引格式,在这种格式中,它会产生顺序文件组织。由于主键是唯一的,并且以排序的方式存储,因此搜索操作的性能非常有效。
2.非聚集索引或二级索引 非聚集索引只是告诉我们数据所在的位置,也就是说,它为我们提供了一个虚拟指针列表或数据实际存储位置的引用。数据不是按索引顺序物理存储的。相反,数据存在于叶节点中。例如,一本书的目录页。每个条目都为我们提供了存储信息的页码或位置。这里的实际数据(本书每页上的信息)没有组织,但我们有一个有序的参考(目录页),指向数据点实际所在的位置。我们只能在非聚集索引中进行密集排序,因为稀疏排序是不可能的,因为数据没有相应的物理组织。 与聚集索引相比,它需要更多的时间,因为为了进一步跟踪指针来提取数据,需要做一些额外的工作。对于聚集索引,数据直接出现在索引前面。
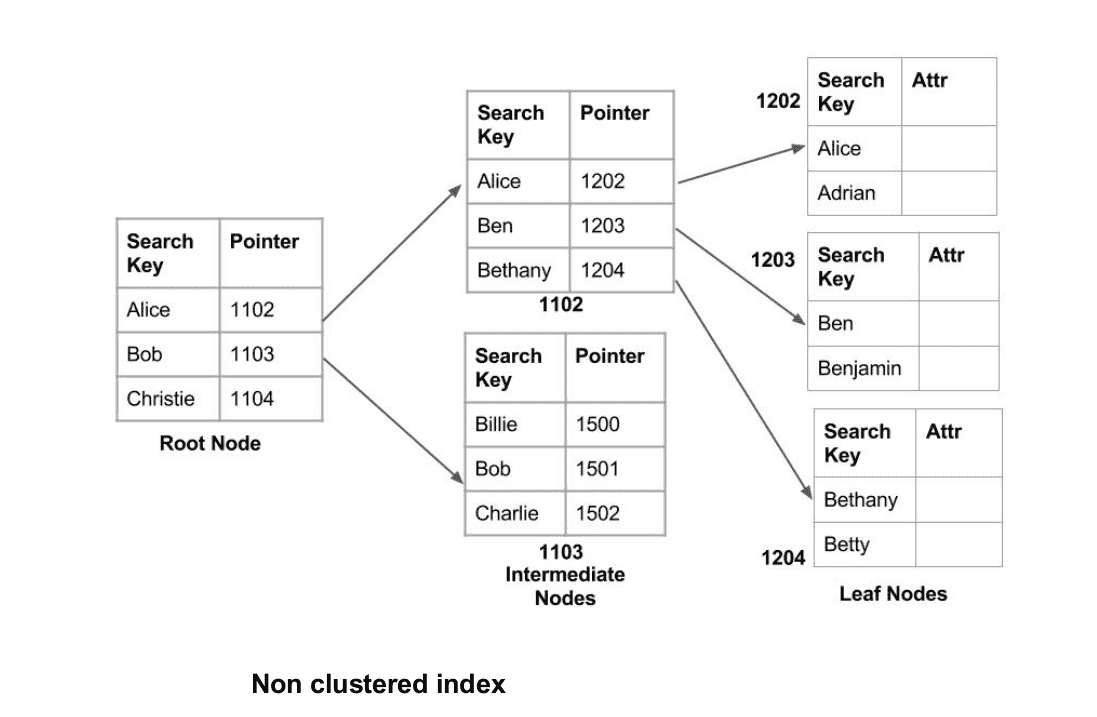
3.多级索引
随着数据库规模的增长,索引也在增长。由于索引存储在主内存中,单个级别的索引可能会变得太大,无法通过多个磁盘访问来存储。多级索引将主块分隔为多个较小的块,以便将其存储在单个块中。外部块分为内部块,内部块依次指向数据块。这可以很容易地存储在主存储器中,开销更少。
![图片[6]-数据库中的索引|集1-yiteyi-C++库](https://media.geeksforgeeks.org/wp-content/cdn-uploads/20190812143045/Untitled-Diagram-41.png)
本文由 阿夫尼特·考尔 。如果您发现任何不正确的地方,或者您想分享有关上述主题的更多信息,请发表评论

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)



