
SQL中的GROUP BY语句在一些函数的帮助下用于将相同的数据分组。i、 e如果一个特定的列在不同的行中有相同的值,那么它将把这些行排列成一个组。
要点:
- GROUP BY子句与SELECT语句一起使用。
- 在查询中,GROUP BY子句放在WHERE子句之后。
- 在查询中,GROUP BY子句放在ORDER BY子句之前(如果有)。
语法 :
SELECT column1, function_name(column2) FROM table_name WHERE condition GROUP BY column1, column2 ORDER BY column1, column2; function_name: Name of the function used for example, SUM() , AVG(). table_name: Name of the table. condition: Condition used.
样本表:
受雇者
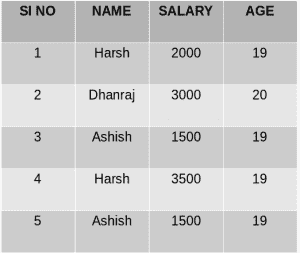
大学生
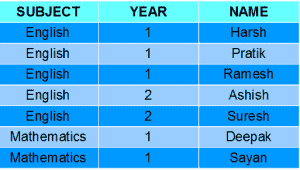 例子:
例子:
- 按单列分组 :Group By single column(按单列分组)的意思是,将只有该特定列具有相同值的所有行放在一个组中。考虑如下所示的查询:
SELECT NAME, SUM(SALARY) FROM Employee GROUP BY NAME;
上述查询将产生以下输出:
 正如您在上面的输出中所看到的,具有重复名称的行被分组在相同的名称下,它们对应的薪资是重复行的薪资之和。这里使用SQL的SUM()函数来计算和。
正如您在上面的输出中所看到的,具有重复名称的行被分组在相同的名称下,它们对应的薪资是重复行的薪资之和。这里使用SQL的SUM()函数来计算和。 - 按多列分组 例如,按组是多列, 按第1栏和第2栏分组 。这意味着放置两列值相同的所有行 专栏1 和 专栏2 一组。考虑下面的查询:
SELECT SUBJECT, YEAR, Count(*) FROM Student GROUP BY SUBJECT, YEAR;
输出 :
 正如你在上面的输出中所看到的,具有相同科目和年份的学生被安排在同一组中。而那些唯一的主题是相同的但不是年份的人属于不同的群体。因此,这里我们根据两列或多列对表进行分组。
正如你在上面的输出中所看到的,具有相同科目和年份的学生被安排在同一组中。而那些唯一的主题是相同的但不是年份的人属于不同的群体。因此,这里我们根据两列或多列对表进行分组。
有从句
我们知道WHERE子句用于在列上放置条件,但如果我们想在组上放置条件呢?
这就是HAVING子句开始使用的地方。我们可以使用HAVING子句来设置条件,以决定哪个组将成为最终结果集的一部分。此外,我们不能将SUM()、COUNT()等聚合函数与WHERE子句一起使用。所以,如果我们想在条件中使用这些函数,我们必须使用HAVING子句。
语法 :
SELECT column1, function_name(column2) FROM table_name WHERE condition GROUP BY column1, column2 HAVING condition ORDER BY column1, column2; function_name: Name of the function used for example, SUM() , AVG(). table_name: Name of the table. condition: Condition used.
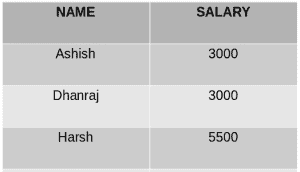
实例 :
SELECT NAME, SUM(SALARY) FROM Employee GROUP BY NAME HAVING SUM(SALARY)>3000;
输出 :  正如您在上面的输出中所看到的,三个组中只有一个组出现在结果集中,因为它是工资总额大于3000的唯一组。所以我们在这里使用HAVING子句来放置这个条件,因为这个条件需要放置在组而不是列上。
正如您在上面的输出中所看到的,三个组中只有一个组出现在结果集中,因为它是工资总额大于3000的唯一组。所以我们在这里使用HAVING子句来放置这个条件,因为这个条件需要放置在组而不是列上。
本文由 严酷的阿加瓦尔 .如果你喜欢GeekSforgek,并想贡献自己的力量,你也可以使用 贡献极客。组织 或者把你的文章寄到contribute@geeksforgeeks.org.看到你的文章出现在Geeksforgeks主页上,并帮助其他极客。
如果您发现任何不正确的地方,或者您想分享有关上述主题的更多信息,请写下评论。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)



