代码生成时间是优化生成的总生成时间的重要贡献者。在编译过程的这一步中,源代码通过几个算法传递,这些算法将您的程序转换为可以更高效地执行的优化版本。一般来说,C++函数的优化很快就会发生,不会带来任何问题。但是,在特殊情况下,有些函数可能变得足够大和复杂,从而对优化器施加压力,并显著降低构建速度。在本文中,我们将展示如何使用C++构建的见解来确定慢代码生成是否对您来说是个问题。我们演示了两种诊断这些问题的方法:首先使用 vcperf公司 分析工具,然后以编程方式使用 C++构建洞察力SDK . 在整个教程中,我们将展示这些技术,这些技术用于将开源JavaScript引擎Chakra的构建时间缩短7%。
如何获取和使用vcperf
本文中的示例使用 vcperf公司 ,该工具允许您捕获构建的跟踪并在 Windows性能分析器(WPA) . 最新版本在VisualStudio2019中提供。
1.按照以下步骤获取和配置 vcperf公司 和水渍险:
- 下载并安装最新版本 Visual Studio 2019 .
- 通过下载和安装 最新Windows ADK .
- 复制
perf_msvcbuildinsights.dll从VisualStudio2019的MSVC安装目录到新安装的WPA目录的文件。这个文件是C++构建的见解WPA插件,它必须可以用于WPA正确显示C++构建洞察力事件。- MSVC的安装目录通常是:
C:Program Files (x86)Microsoft Visual Studio2019{Edition}VCToolsMSVC{Version}inHostx64x64. - WPA的安装目录通常是:
C:Program Files (x86)Windows Kits10Windows Performance Toolkit.
- MSVC的安装目录通常是:
- 打开
perfcore.ini文件,并为perf_msvcbuildinsights.dll文件。这告诉WPA在启动时加载C++构建透视插件。
您还可以获得最新的 vcperf公司 通过克隆和构建 vcperf GitHub存储库 . 您可以将构建的副本与Visual Studio 2019结合使用!
2.按照以下步骤收集构建的跟踪:
- 打开高架门 用于VS 2019的x64本机工具命令提示符 .
- 获取您的版本的跟踪:
- 运行以下命令:
vcperf /start MySessionName. - 从任何地方构建您的C++项目,甚至从VisualStudio中构建 vcperf公司 收集系统范围内的事件)。
- 运行以下命令:
vcperf /stop MySessionName outputFile.etl. 此命令将停止跟踪,分析所有事件,并保存 输出文件.etl 跟踪文件。
- 运行以下命令:
- 打开你刚刚在WPA中收集的跟踪。
在WPA中使用函数视图
C++构建见解有一个专门的视图来帮助诊断慢代码生成时间: 功能 查看。在WPA中打开跟踪后,可以通过从 图形浏览器 窗格到 分析 窗口,如下所示。
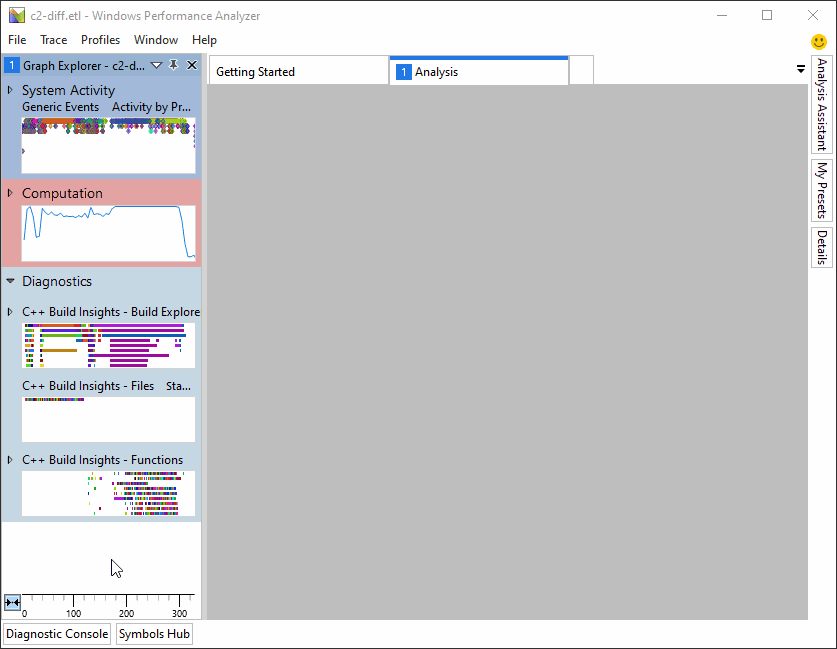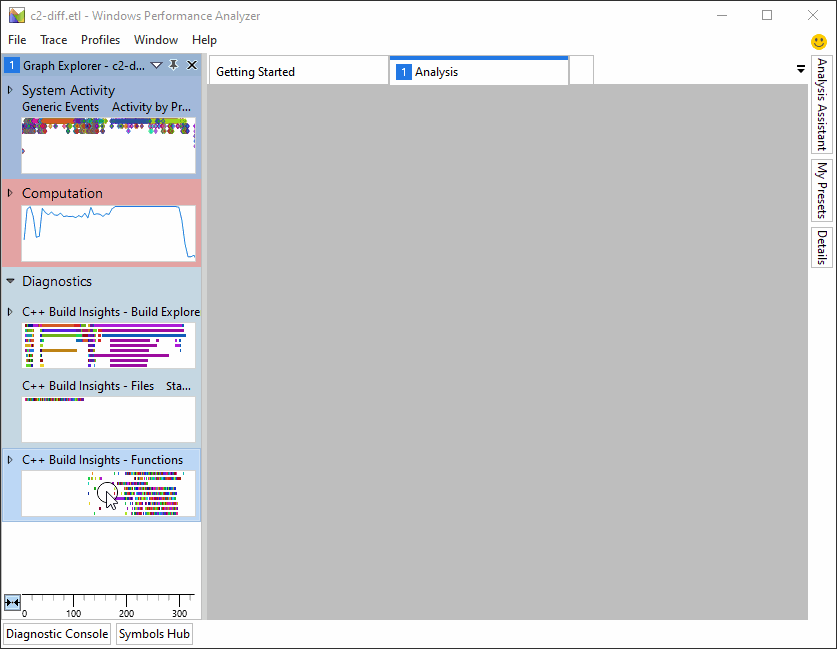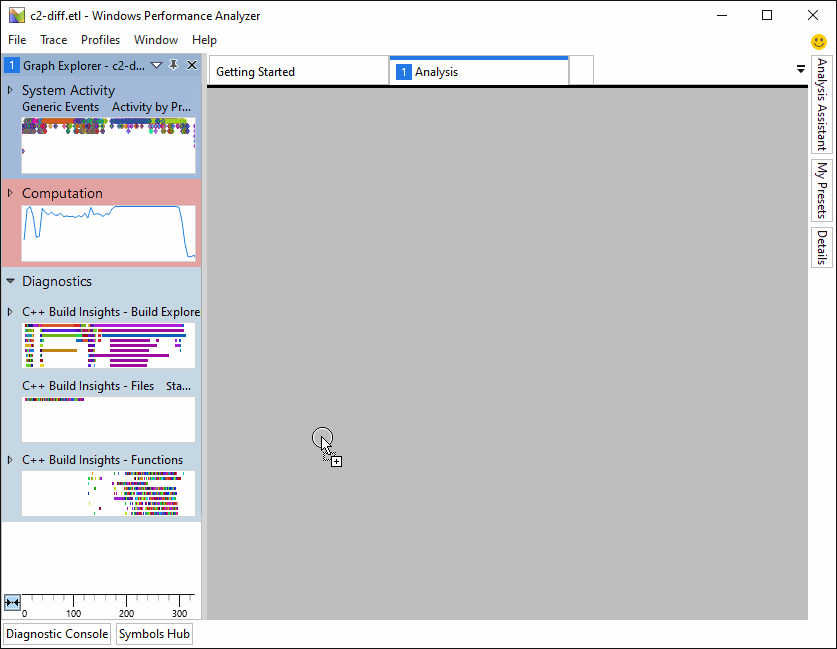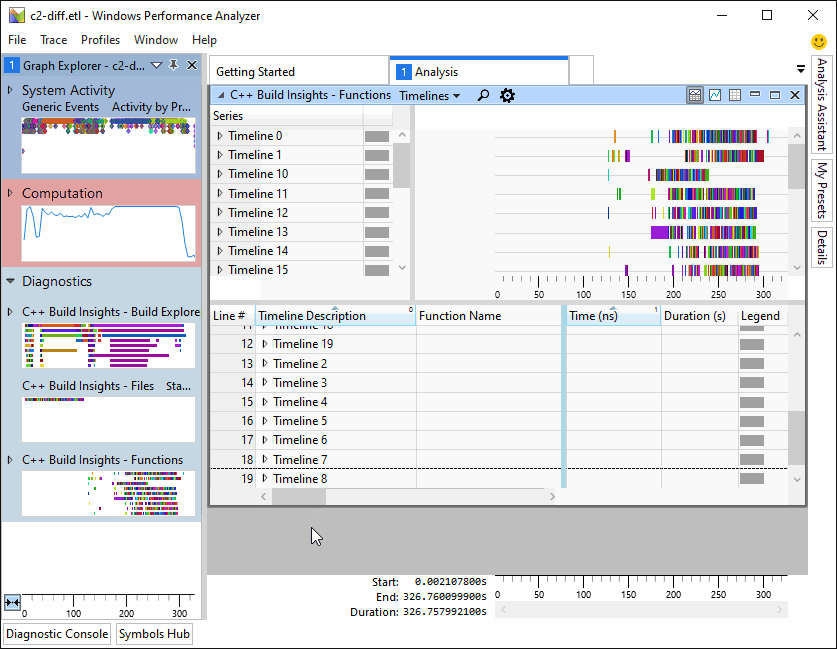
“函数”视图提供了3个预设,您可以在浏览生成跟踪时从中进行选择:
- 时间表
- 活动统计
- 力内线
单击视图顶部的下拉菜单以选择所需的视图。此步骤如下所示。
在接下来的3节中,我们依次介绍这些预设。
预设#1:时间线
当 时间表 如果“预设”处于活动状态,请将注意力集中在视图顶部的“图形”部分。它概述了在并行构建中出现函数代码生成瓶颈的地方。每个时间线代表一个线程。时间线编号与 生成资源管理器视图 . 在这个图中,一个彩色条表示一个正在优化的函数。条越长,优化此函数所花费的时间就越多。将鼠标悬停在每个彩色条上,以查看正在优化的函数的名称。棒在x轴上的位置表示函数优化开始的时间。放置 功能 a下方视图 生成资源管理器 查看以了解函数的代码生成如何影响整个构建,以及它是否是一个瓶颈。这个 时间表 预设如下图所示。
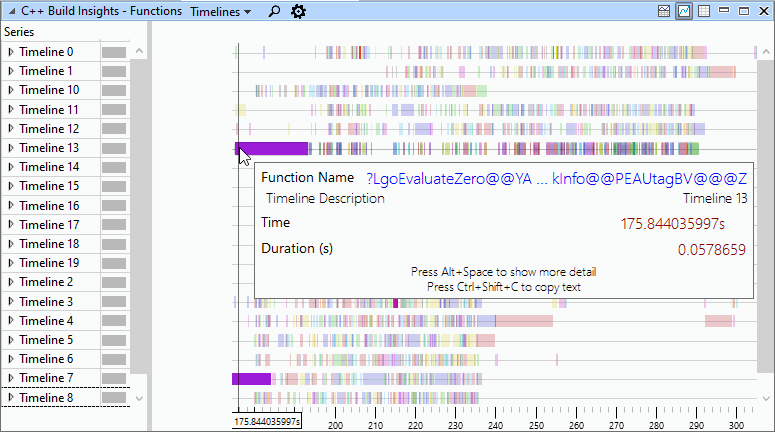
注意。 代码生成的精确并行性仅从VisualStudio2019版本16.4开始提供。在早期版本中,给定编译器或链接器调用的所有代码生成线程都放在一个时间线上。在16.4及更高版本中,编译器或链接器调用中的每个代码生成线程都放在自己的时间线上。
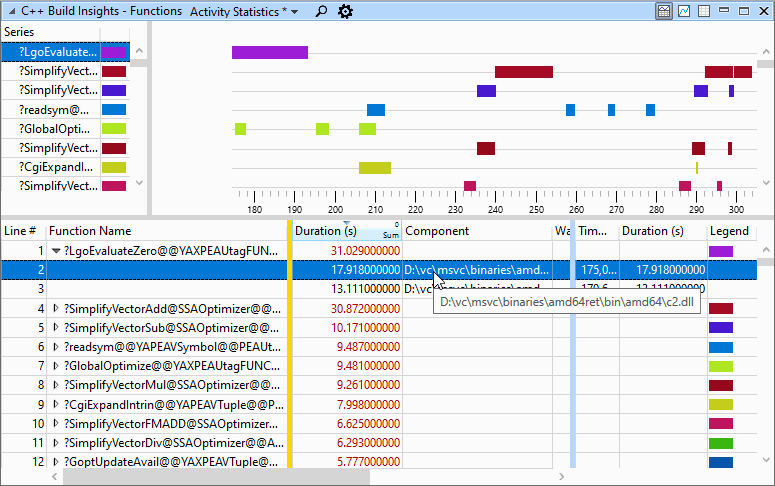
预设#2:活动统计
这个 活动统计 预设显示生成中函数的代码生成统计信息。使用此预设时,请将注意力集中在视图底部的表上。默认情况下,函数按其代码生成持续时间降序排序。如果您想快速确定在整个构建中花费最多时间优化的函数,请使用此预设。如果您只对构建的一部分感兴趣,请单击并将鼠标拖动到视图顶部图形部分中所需的时间跨度上。图表下表中的值将自动调整为选定的时间跨度。该表显示统计信息,例如:代码生成时间、在其中找到函数的文件或DLL,以及在生成函数期间执行的编译器或链接器调用。使用 生成资源管理器视图 以获取有关调用的更多信息(如果需要)。类似于 时间表 预设时,视图顶部图形部分中的彩色条表示给定函数的代码生成发生的时间和持续时间,但信息是按函数名而不是按线程分组的。这个 活动统计 预设如下所示。
预设#3:强制输入线
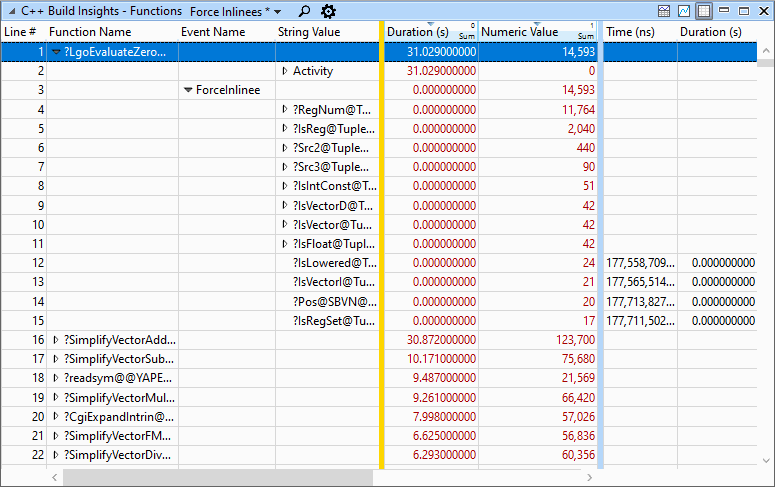
将大型函数调用图内联到单个根函数中会导致非常大的函数需要很长时间才能优化。过度使用 __forceinline 关键字是这个问题的常见原因,因此C++构建见解包括一个专用的预置来快速识别力内联问题。当使用 力内线 预设,将注意力集中在视图底部的桌子上。展开函数及其 强制线 节点以查看已强制内联在其中的所有其他函数。没有任何强制内线的函数将被过滤掉。这个 字符串值 字段包含力inline的名称,以及 数值 字段指示此力inlinee导致根级别函数的大小增长的程度。这个 数值 大致相当于内联函数中的中间指令数,因此越高越好。力内线按大小排序(即。 数值 )按降序排列,可以让您快速看到最严重的违规者。使用此信息尝试删除一些 __forceinline 关于大函数的关键字。这些函数不会受到太多调用开销的影响,如果忽略内联,则不太可能导致性能下降。使用时要小心 数值 字段,因为同一函数可以多次强制内联 数值 默认情况下是总和聚合。展开 字符串值 列以查看同名所有内联线的单个大小。这个 力内线 预设如下所示。
关于“函数”视图中显示的函数名的注释
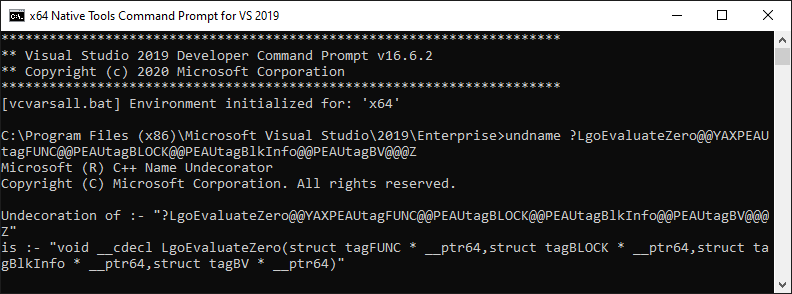
这个 功能 视图显示了被破坏的C++函数名。你可以用 域名 实用程序来定义名称。为此,在WPA中包含名称的单元格上单击鼠标右键,然后单击 复制单元格 ,并将该值传递给 域名 ,如下所示。这个 域名 实用程序在 用于VS 2019的x64本机工具命令提示符 .
把它们放在一起:使用函数视图来加速脉轮构建
在本案例研究中,我们使用来自GitHub的Chakra开源JavaScript引擎来演示 vcperf公司 可用于实现7%的构建时间改进。
如果您想按照以下步骤操作:
- 克隆 ChakraCore GitHub存储库 .
- 将目录更改为新克隆的存储库的根目录,然后运行以下命令:
git checkout c72b4b7. 这是用于下面的案例研究的提交。 - 打开
BuildChakra.Core.sln解决方案文件,从存储库的根目录开始。 - 获取解决方案完整重建的跟踪:
- 打开提升的命令提示符 vcperf公司 在路上。
- 运行以下命令:
vcperf /start Chakra - 重建 x64试验 设备的配置
BuildChakra.Core.slnVisual Studio 2019中的解决方案文件。 - 运行以下命令:
vcperf /stop Chakra chakra.etl. 这将保存内建的跟踪 脉轮.etl .
- 在WPA中打开跟踪。
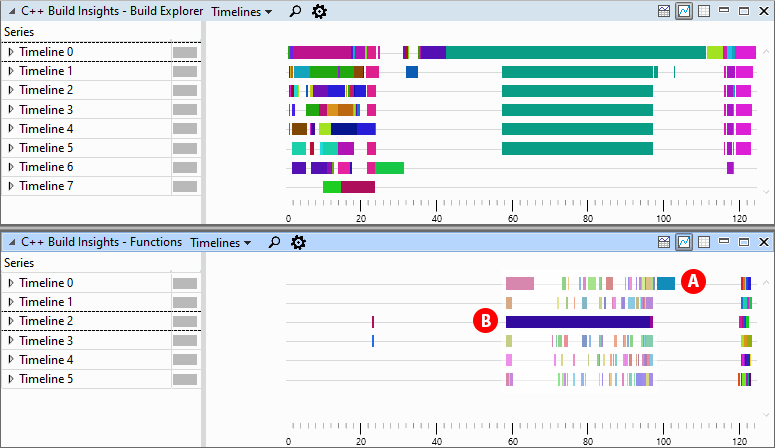
我们带来了 生成资源管理器 和 功能 视图,并将它们一个放在另一个上。这个 功能 视图显示了两个长代码生成活动,标记为 A 和 B 在下面。这些活动与 生成资源管理器 上图。我们推测减少代码生成时间 A 和 B 应该有助于总的构建时间,因为他们在关键路径上。让我们进一步调查。
我们切换到 活动统计 预设在 功能 查看,并找出这两个函数对应的 A 和 B 被命名为 infos_ 和 GetToken 分别是。
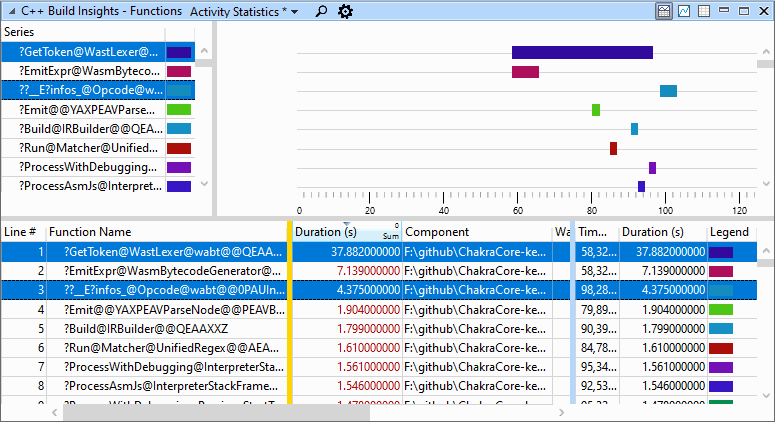
修复信息:在编译时评估初始值设定项
看看脉轮的密码,我们发现 infos_ 是一个大型的全局数组 Opcode::Info 物体。定义见 libwabtsrcopcode.cc ,如下所示。这个 Opcode::Info 元素使用中的450多个条目进行初始化 libwabtsrcopcode.def .
// static
Opcode::Info Opcode::infos_[] = {
#define WABT_OPCODE(rtype, type1, type2, type3, mem_size, prefix, code, Name,
text)
{text, Type::rtype, Type::type1,
Type::type2, Type::type3, mem_size,
prefix, code, PrefixCode(prefix, code)},
#include "src/opcode.def"
#undef WABT_OPCODE
{"<invalid>", Type::Void, Type::Void, Type::Void, Type::Void, 0, 0, 0, 0},
};
这个数组与 infos_ 我们在脉轮轨迹中看到的功能?为什么这个函数产生得慢?
全局变量有时不能在编译时初始化,因为它们的初始化需要执行一些代码(例如构造函数)。在这种情况下,编译器生成一个称为动态初始值设定项的函数,该函数将在程序启动期间调用,以正确初始化变量。您可以很容易地识别 功能 因为他们的名字总是以 ??__E .
我们之前捕捉到的脉轮轨迹告诉我们,一个动态初始化函数是为 infos_ . 生成此函数需要很长时间的原因是450+元素的初始化代码 infos_ 数组非常大,导致编译器的优化阶段需要更多时间才能完成。
如果是 infos_ ,初始化其元素所需的所有信息在编译时都是已知的。通过强制编译时初始化,可以防止生成动态初始值设定项,如下所示:
- (可选)使
infos_数组constexpr; 和 - 制造
PrefixCode功能constexpr.
步骤1之所以是个好主意,是因为如果 infos_ 任何错误的更改都会阻止编译时初始化。没有它,编译器将自动恢复为生成动态初始值设定项函数。步骤2是必需的,因为 PrefixCode 在每个 Opcode::Info 元素的编译时初始化 infos_ 如果其初始化的任何部分未被初始化,则无法发生 constexpr .
看到了吗 GitHub上此修复程序的代码 .
修复GetToken:对大型函数使用简化优化器
的C代码 GetToken 是由 re2c型 开源软件lexer生成器。结果函数非常大,并且由于其大小而遭受长时间的优化。因为C代码是生成的,所以用一种可以解决构建时问题的方法来修改它可能不是一件小事。当出现这种情况时,您可以使用 ReducedOptimizeHugeFunctions 开关。此开关可防止优化器对大型函数使用昂贵的优化,从而缩短优化时间。您可以使用 ReducedOptimizeThreshold:# 开关。 # 是函数在触发精简优化器之前必须拥有的指令数。默认值为20000。
- 使用链接时代码生成(LTCG)构建时,使用将这些开关传递给链接器
/d2:”-ReducedOptimizeHugeFunctions”和/d2:”-ReducedOptimizeThreshold:#”. - 在没有LTCG的情况下构建时,使用将这些开关传递给编译器
/d2ReducedOptimizeHugeFunctions和/d2ReducedOptimizeThreshold:#.
对于我们的Chakra示例,我们使用visualstudio2019修改ChakraCore项目的属性并添加 /d2:”-ReducedOptimizeHugeFunctions” 开关,如下所示。因为我们正在构建的配置使用LTCG,所以交换机被添加到链接器中。
![图片[9]-用C++构建洞察力提高代码生成时间-yiteyi-C++库](https://devblogs.microsoft.com/cppblog/wp-content/uploads/sites/9/2020/07/word-image-8.gif)
注意。 使用 ReducedOptimizeHugeFunctions 对于大型函数,切换可能会降低生成代码的性能。如果对性能关键型代码使用此开关,请考虑在更改前后分析代码,以确保差异是可接受的。
看到了吗 GitHub上此修复程序的代码 .
替代解决方案:拆分代码并删除
您可能无法在项目中使用上述方法。这可能是因为:
- 您有无法在编译时初始化的大型全局数组;或
- 由于使用
ReducedOptimizeHugeFunctions开关不可接受。
函数的代码生成速度慢几乎总是因为函数太大。任何减小函数大小的方法都会有所帮助。考虑以下替代解决方案:
- 手动将一个非常大的函数拆分为两个或更多单独调用的子函数。这种分裂技术也可用于大型全局阵列。
- 使用 力内线 系统预置 功能 查看是否过度使用
__forceinline关键字可能是罪魁祸首。如果是,请尝试删除__forceinline从最大力内联函数。
注意。 替代方案2可能会导致性能下降,如果 __forceinline 从经常强制内联的小函数中删除。最好在大力内联函数上使用此解决方案。
评估我们的脉轮解决方案
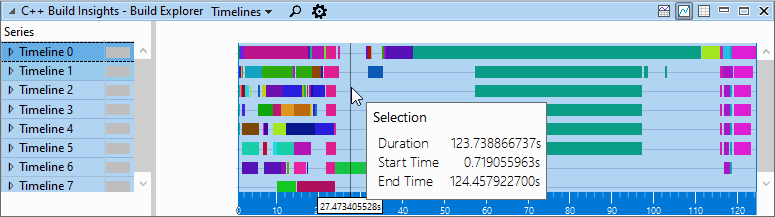
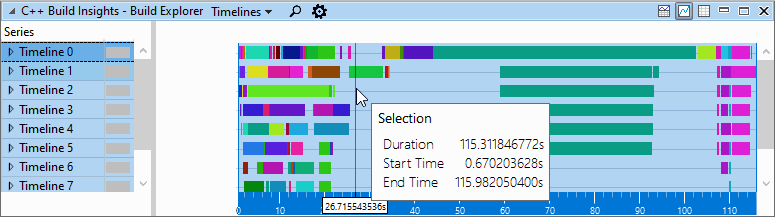
在修复了的动态初始值设定项之后,我们捕获了另一个跟踪 infos__ 使用 ReducedOptimizeHugeFunctions 开关 GetToken . 比较 生成资源管理器 更改前后的视图显示,总构建时间从124秒减少到115秒,减少了7%。
应用解决方案前生成资源管理器视图:
应用解决方案后生成资源管理器视图:
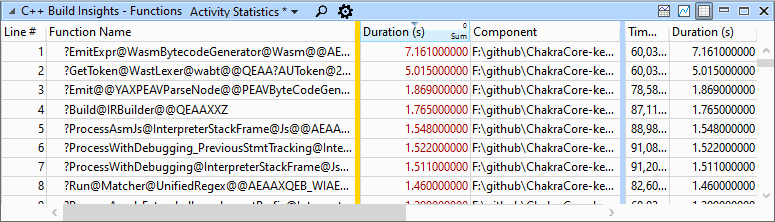
这个 活动统计 在我们的 功能 固定跟踪视图显示 infos__ 已经不存在了 GetToken 的代码生成时间减少到5秒左右。
使用C++构建洞察SDK识别慢代码生成
有时,自动检测代码生成时间较长的函数可能很有用,而不必检查WPA中的跟踪。例如,您可能希望在连续集成(CI)期间或本地将有问题的函数标记为生成后步骤。这个 C++构建洞察力SDK 启用这些方案。为了说明这一点,我们准备了 功能瓶颈 SDK示例。当传递一个跟踪时,它将打印一个函数列表,这些函数的持续时间至少为1秒,并且超过其包含的函数持续时间的5% cl.exe文件 属于 链接程序 调用。函数列表按持续时间降序排列。因为慷慨地使用 __forceinline 是导致函数优化缓慢的常见原因,在强制内联可能存在问题的每个条目旁边都会放置一个星号。
让我们重复上一节中的脉轮案例研究,但这次使用 功能瓶颈 取样看看有什么发现 . 如果您想继续,请使用以下步骤:
- 克隆 C++构建洞察力SDK示例GITHUB库 在你的机器上。
- 构建` 示例.sln` 解决方案,针对所需的体系结构(x86或x64),并使用所需的配置(调试或发布)。示例的可执行文件将放置在
out/{architecture}/{configuration}/FunctionBottlenecks文件夹,从存储库的根目录开始。 - 按照 把它们放在一起:使用函数视图来加速脉轮构建 收集脉轮溶液的痕迹。使用
/stopnoanalyze命令而不是/stop停止跟踪时的命令。这个/stopnoanalyze命令用于获取与SDK兼容的跟踪。 - 将收集到的跟踪作为第一个参数传递给 功能瓶颈 可执行文件。
如下所示,当传递未修改项目的跟踪时, 功能瓶颈 正确识别 GetToken 函数及其动态分析仪 infos_ 数组。
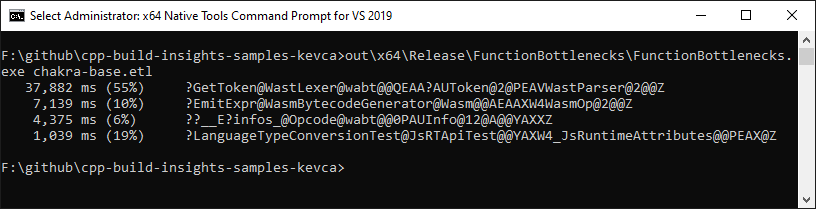
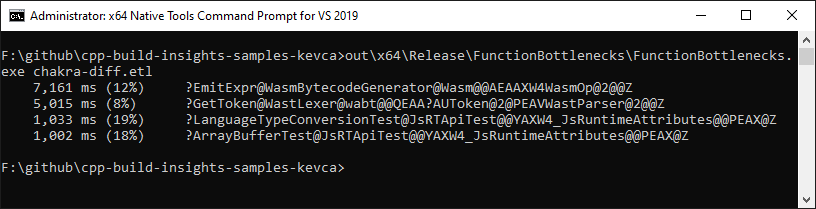
在应用了本文中描述的解决方案之后 功能瓶颈 样本确认情况有所改善: GetToken 从38秒降到5秒 infos_ 已经不是问题了。
查看示例代码
这个 功能瓶颈 analyzer分两次处理跟踪。第一个过程由两个成员函数完成。首先是 OnStopInvocation 用于缓存所有调用的持续时间。
void OnStopInvocation(Invocation invocation)
{
using namespace std::chrono;
// Ignore very short invocations
if (invocation.Duration() < std::chrono::seconds(1)) {
return;
}
cachedInvocationDurations_[invocation.EventInstanceId()] =
duration_cast<milliseconds>(invocation.Duration());
}
第二个是 ProcessForceInlinee 和用于缓存强制内联到给定顶级函数中的所有函数的聚合大小。
void ProcessForceInlinee(Function func, ForceInlinee inlinee)
{
forceInlineSizeCache_[func.EventInstanceId()] +=
inlinee.Size();
}
第二步是根据第1步中收集的信息来决定函数是否是瓶颈 OnStopFunction .
void OnStopFunction(Invocation invocation, Function func)
{
using namespace std::chrono;
auto itInvocation = cachedInvocationDurations_.find(
invocation.EventInstanceId());
if (itInvocation == cachedInvocationDurations_.end()) {
return;
}
auto itForceInlineSize = forceInlineSizeCache_.find(
func.EventInstanceId());
unsigned forceInlineSize =
itForceInlineSize == forceInlineSizeCache_.end() ?
0 : itForceInlineSize->second;
milliseconds functionMilliseconds =
duration_cast<milliseconds>(func.Duration());
double functionTime = static_cast<double>(
functionMilliseconds.count());
double invocationTime = static_cast<double>(
itInvocation->second.count());
double percent = functionTime / invocationTime;
if (percent > 0.05 && func.Duration() >= seconds(1))
{
identifiedFunctions_[func.EventInstanceId()]=
{ func.Name(), functionMilliseconds, percent,
forceInlineSize };
}
}
如上所示,瓶颈函数被添加到 identifiedFunctions_ 容器。这个容器是一个 std::unordered_map 保存类型值的 IdentifiedFunction .
struct IdentifiedFunction
{
std::string Name;
std::chrono::milliseconds Duration;
double Percent;
unsigned ForceInlineeSize;
bool operator<(const IdentifiedFunction& other) const {
return Duration > other.Duration;
}
};
我们使用 OnEndAnalysis 从 IAnalyzer 接口按持续时间降序排列已识别的函数,并将列表打印到标准输出。
AnalysisControl OnEndAnalysis() override
{
std::vector<IdentifiedFunction> sortedFunctions;
for (auto& p : identifiedFunctions_) {
sortedFunctions.push_back(p.second);
}
std::sort(sortedFunctions.begin(), sortedFunctions.end());
for (auto& func : sortedFunctions)
{
bool forceInlineHeavy = func.ForceInlineeSize >= 10000;
std::string forceInlineIndicator = forceInlineHeavy ?
", *" : "";
int percent = static_cast<int>(func.Percent * 100);
std::string percentString = "(" +
std::to_string(percent) + "%" +
forceInlineIndicator + ")";
std::cout << std::setw(9) << std::right <<
func.Duration.count();
std::cout << " ms ";
std::cout << std::setw(9) << std::left <<
percentString;
std::cout << " " << func.Name << std::endl;
}
return AnalysisControl::CONTINUE;
}
告诉我们你的想法!
我们希望本文中的信息能够帮助您理解如何使用 功能 查看 vcperf公司 和WPA来诊断构建中的代码生成缓慢。我们也希望所提供的SDK示例可以作为建立自己分析器的良好基础。
给予 vcperf公司 今天下载最新版本的 Visual Studio 2019 ,或直接从 vcperf GitHub存储库 . 试试这个 功能瓶颈 通过克隆 C++构建洞察力示例库 从GitHub,或参考官方 C++构建洞察SDK文档 建立自己的分析工具。
您是否发现使用 vcperf公司 还是C++构建洞察力SDK?让我们知道在下面的评论,在Twitter上 (@VisualC) ),或通过电子邮件 visualcpp@microsoft.com .
本文包含 WABT:WebAssembly二进制工具箱 ,版权所有(c)2015-2020 WebAssembly社区组参与者,根据 Apache许可证,2.0版 .

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)