出身背景
数据库和web服务器等服务器程序反复执行来自多个客户机的请求,这些程序面向处理大量短任务。构建服务器应用程序的一种方法是在每次请求到达时创建一个新线程,并在新创建的线程中为这个新请求提供服务。虽然这种方法似乎很容易实现,但它有很大的缺点。与处理实际请求相比,为每个请求创建新线程的服务器在创建和销毁线程时会花费更多的时间和消耗更多的系统资源。
由于活动线程消耗系统资源,因此 JVM 同时创建太多线程可能会导致系统内存不足。这就需要限制正在创建的线程的数量。
什么是Java中的线程池?
线程池重用以前创建的线程来执行当前任务,并为线程周期开销和资源波动问题提供了解决方案。 由于当请求到达时线程已经存在,因此线程创建所引入的延迟被消除,从而使应用程序更具响应性。
- Java提供了以Executor接口为中心的Executor框架,它的子接口—— 遗嘱执行人服务 还有这个班- 线程池 ,它实现了这两个接口。通过使用executor,只需实现可运行对象并将其发送给executor即可执行。
- 它们允许您利用线程,但专注于希望线程执行的任务,而不是线程机制。
- 要使用线程池,我们首先创建ExecutorService对象,并向其传递一组任务。ThreadPoolExecutor类允许设置核心池和最大池大小。由特定线程运行的可运行程序是按顺序执行的。
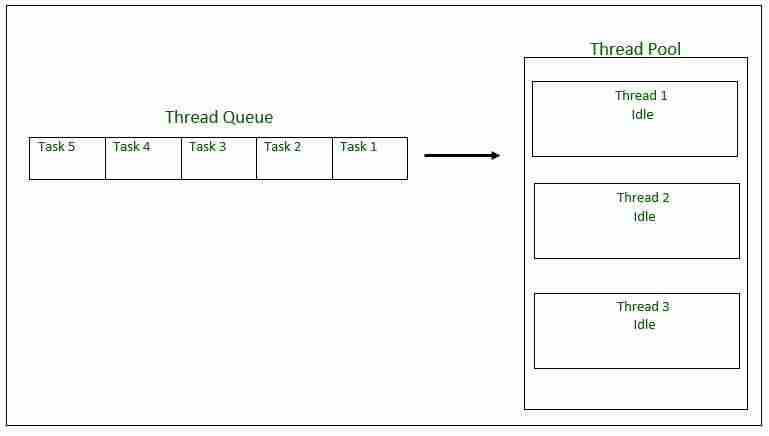
线程池初始化,大小为3个线程。任务队列=5个可运行对象
执行器线程池方法
Method Description newFixedThreadPool(int) Creates a fixed size thread pool. newCachedThreadPool() Creates a thread pool that creates new threads as needed, but will reuse previously constructed threads when they are available newSingleThreadExecutor() Creates a single thread.在固定线程池的情况下,如果所有线程当前都由执行器运行,那么挂起的任务将被放置在队列中,并在线程空闲时执行。
线程池示例
在下面的教程中,我们将看一个线程池执行器的基本示例-FixedThreadPool。
应遵循的步骤
1. Create a task(Runnable Object) to execute 2. Create Executor Pool using Executors 3. Pass tasks to Executor Pool 4. Shutdown the Executor Pool
// Java program to illustrate// ThreadPoolimportjava.text.SimpleDateFormat;importjava.util.Date;importjava.util.concurrent.ExecutorService;importjava.util.concurrent.Executors;// Task class to be executed (Step 1)classTaskimplementsRunnable{privateString name;publicTask(String s){name = s;}// Prints task name and sleeps for 1s// This Whole process is repeated 5 timespublicvoidrun(){try{for(inti =0; i<=5; i++){if(i==0){Date d =newDate();SimpleDateFormat ft =newSimpleDateFormat("hh:mm:ss");System.out.println("Initialization Time for"+" task name - "+ name +" = "+ft.format(d));//prints the initialization time for every task}else{Date d =newDate();SimpleDateFormat ft =newSimpleDateFormat("hh:mm:ss");System.out.println("Executing Time for task name - "+name +" = "+ft.format(d));// prints the execution time for every task}Thread.sleep(1000);}System.out.println(name+" complete");}catch(InterruptedException e){e.printStackTrace();}}}publicclassTest{// Maximum number of threads in thread poolstaticfinalintMAX_T =3;publicstaticvoidmain(String[] args){// creates five tasksRunnable r1 =newTask("task 1");Runnable r2 =newTask("task 2");Runnable r3 =newTask("task 3");Runnable r4 =newTask("task 4");Runnable r5 =newTask("task 5");// creates a thread pool with MAX_T no. of// threads as the fixed pool size(Step 2)ExecutorService pool = Executors.newFixedThreadPool(MAX_T);// passes the Task objects to the pool to execute (Step 3)pool.execute(r1);pool.execute(r2);pool.execute(r3);pool.execute(r4);pool.execute(r5);// pool shutdown ( Step 4)pool.shutdown();}}样本执行
Output: Initialization Time for task name - task 2 = 02:32:56 Initialization Time for task name - task 1 = 02:32:56 Initialization Time for task name - task 3 = 02:32:56 Executing Time for task name - task 1 = 02:32:57 Executing Time for task name - task 2 = 02:32:57 Executing Time for task name - task 3 = 02:32:57 Executing Time for task name - task 1 = 02:32:58 Executing Time for task name - task 2 = 02:32:58 Executing Time for task name - task 3 = 02:32:58 Executing Time for task name - task 1 = 02:32:59 Executing Time for task name - task 2 = 02:32:59 Executing Time for task name - task 3 = 02:32:59 Executing Time for task name - task 1 = 02:33:00 Executing Time for task name - task 3 = 02:33:00 Executing Time for task name - task 2 = 02:33:00 Executing Time for task name - task 2 = 02:33:01 Executing Time for task name - task 1 = 02:33:01 Executing Time for task name - task 3 = 02:33:01 task 2 complete task 1 complete task 3 complete Initialization Time for task name - task 5 = 02:33:02 Initialization Time for task name - task 4 = 02:33:02 Executing Time for task name - task 4 = 02:33:03 Executing Time for task name - task 5 = 02:33:03 Executing Time for task name - task 5 = 02:33:04 Executing Time for task name - task 4 = 02:33:04 Executing Time for task name - task 4 = 02:33:05 Executing Time for task name - task 5 = 02:33:05 Executing Time for task name - task 5 = 02:33:06 Executing Time for task name - task 4 = 02:33:06 Executing Time for task name - task 5 = 02:33:07 Executing Time for task name - task 4 = 02:33:07 task 5 complete task 4 complete
从程序的执行中可以看出,任务4或任务5仅在池中的线程空闲时执行。在此之前,额外的任务都会排在队列中。
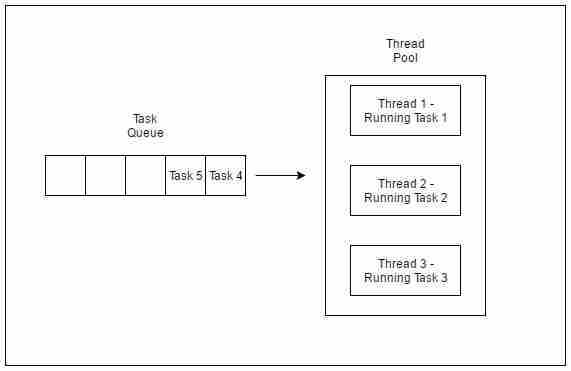
执行前三个任务的线程池
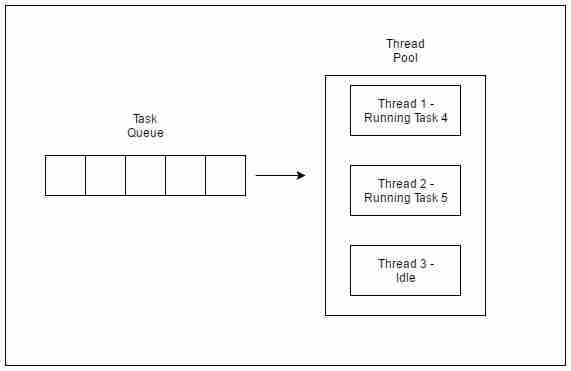
执行任务4和5的线程池
One of the main advantages of using this approach is when you want to process 100 requests at a time, but do not want to create 100 Threads for the same, so as to reduce JVM overload. You can use this approach to create a ThreadPool of 10 Threads and you can submit 100 requests to this ThreadPool. ThreadPool will create maximum of 10 threads to process 10 requests at a time. After process completion of any single Thread, ThreadPool will internally allocate the 11th request to this Thread and will keep on doing the same to all the remaining requests.
使用线程池的风险
- 僵局 : 虽然死锁可以发生在任何多线程程序中,但线程池会引入另一种死锁情况,即由于线程不可用,所有执行线程都在等待队列中等待的阻塞线程的结果。
- 螺纹泄漏: 如果从池中移除线程以执行任务,但在任务完成时未将其返回,则会发生线程泄漏。例如,如果线程抛出一个异常,而池类没有捕获该异常,那么线程将直接退出,从而将线程池的大小减少一个。如果这种情况重复多次,那么池最终将变为空,并且没有线程可用于执行其他请求。
- 资源冲击: 如果线程池的大小非常大,那么在线程之间切换上下文会浪费时间。如前所述,拥有超过最佳数量的线程可能会导致饥饿问题,从而导致资源浪费。
要点
- 不要对同时等待其他任务结果的任务排队。这可能会导致如上所述的死锁情况。
- 使用线程进行长期操作时要小心。这可能会导致线程永远等待,并最终导致资源泄漏。
- 线程池必须在末尾显式结束。如果不这样做,程序就会继续执行,永远不会结束。对池调用shutdown()以结束执行器。如果您试图在关机后向执行器发送另一个任务,它将抛出RejectedExecutionException。
- 需要了解任务才能有效地优化线程池。如果任务之间有很大的差异,那么对不同类型的任务使用不同的线程池是有意义的,以便对它们进行适当的调整。
- 可以限制在JVM中运行的线程的最大数量,减少JVM内存不足的可能性。
- 如果需要实现循环来创建新线程以进行处理,那么使用ThreadPool将有助于加快处理速度,因为ThreadPool在达到其最大限制后不会创建新线程。
- 线程处理完成后,ThreadPool可以使用同一个线程执行另一个进程(这样可以节省创建另一个线程的时间和资源)
调整线程池
- 线程池的最佳大小取决于可用处理器的数量和任务的性质。对于只包含计算类型进程的队列,在N处理器系统上,最大线程池大小为N或N+1将实现最大效率。但任务可能会等待I/O,在这种情况下,我们会考虑请求的等待时间(W)和服务时间(S)的比率;最大池大小为N*(1+W/S),以实现最大效率。
线程池是组织服务器应用程序的有用工具。它在概念上非常简单,但在实现和使用它时,有几个问题需要注意,比如死锁、资源浪费。executor服务的使用使其更易于实现。
本文由 阿披实 .如果你喜欢GeekSforgek,并想贡献自己的力量,你也可以使用 贡献极客。组织 或者把你的文章寄到contribute@geeksforgeeks.org.看到你的文章出现在Geeksforgeks主页上,并帮助其他极客。
如果您发现任何不正确的地方,或者您想分享有关上述主题的更多信息,请写下评论。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)