Awk是非常流行和有用的文本和字符串操作工具。Regex或正则表达式是用于定义文本和字符串结构的通用语言。Awk罐
语法
awk的正则表达式可以与以下语法一起使用。
awk '/REGULAR_EXPRESSION/'
-
REGULAR_EXPRESSION是我们要运行的正则表达式。正则表达式被/和/
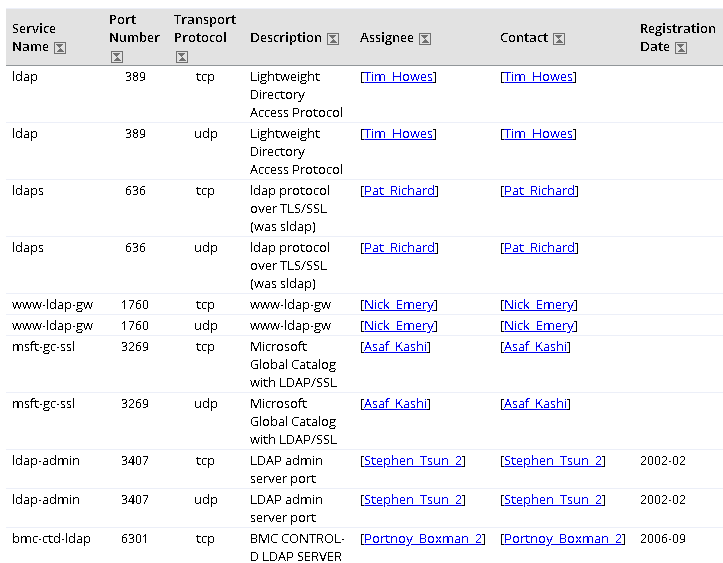
示例数据
我们将使用名为 data.txt 例如脚本。
ismail 33 male ahmet 5 male elif 8 female
任何单个字符
正则表达式的第一个也是最简单的例子是用正则表达式表示单个字符。在这篇文章中,我们将从 is 结束于 ail 但包含单个字符之间则字符不重要。
$ awk '/is.ail/' data.txt

线路起点
我们可能需要指定行的起点。我们将使用 ^ sig指定行的开始。在本例中,我们将查看以开头的行 a .
$ awk '/^a/' data.txt

行尾
像前面的例子一样,我们也可以用 $ 签字。在本例中,我们将查看以 le .
$ awk '/le$/' data.txt

匹配字符集
我们可以指定多个字符来匹配其中一个。我们将把这些角色放到 [...] . 在这个例子中,我们将匹配那些 sm 或 hm .
$ awk '/[sh]m/' data.txt

独占集
排他集是字符集的逆运算。提供的匹配行集将从输出中删除。我们将把独家套餐快递为 [^...] . 在本例中,我们希望列出那些没有的行 sm 或 hm .
$ awk '/[^sh]m/' data.txt
或多个单词
我们可以为单个搜索操作指定多个单词。这将匹配所有具有所提供单词之一的行。在这个例子中,我们将匹配线 ahmet 或 ismail
$ awk "/ismail|ahmet/" data.txt

匹配零次或一次出现
我们可以指定期望给定字符出现零次或一次。我们将使用 ? 签字。在这个例子中,我们将看到 i 字符零或一次出现。
$ awk "/l?i/" data.txt

匹配零次或多次出现
我们可以使用 * 签字。在本例中,我们将查找单词 male , malee , maleee , …
$ awk "/male*/" data.txt

匹配一个或多个引用
我们也可以期望给定的字符或单词出现一次或多次。我们将使用 + 为了这个。在这个例子中,我们将看到 male , mmale , mmmale .
$ awk "/m*ale/" data.txt

匹配组
到目前为止,我们通常使用单个字符,但在现实世界中,我们可能需要多个字符或单词来匹配。我们将使用 (...) . 在本例中,我们将查看 male .
$ awk "/(male)+/" data.txt


![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)