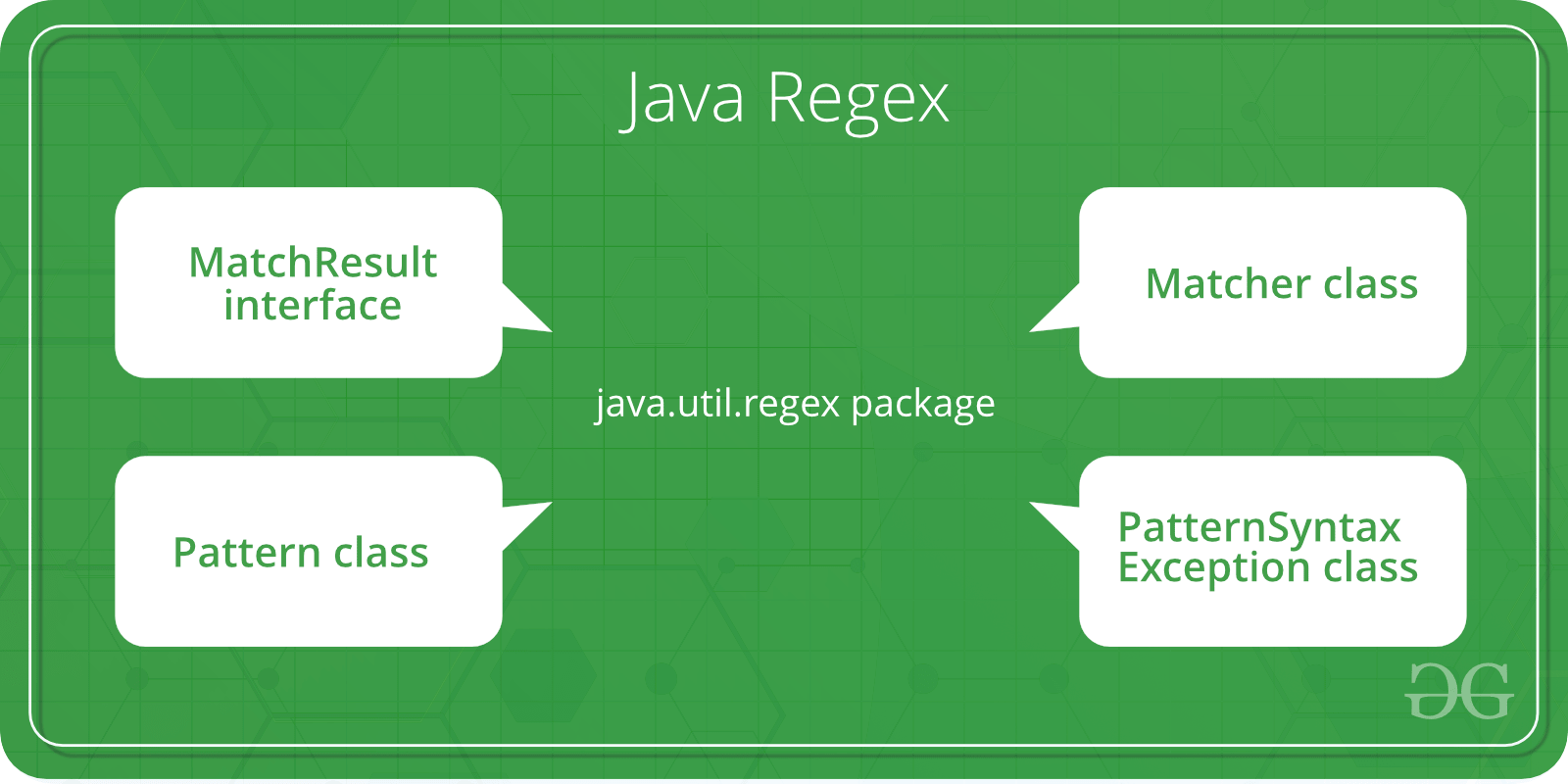
Java中的正则表达式或正则表达式(简而言之)是定义字符串模式的API,可用于在Java中搜索、操作和编辑字符串。电子邮件验证和密码是字符串的几个领域,在这些领域中,Regex被广泛用于定义约束。正则表达式在下面提供 JAVAutil。正则表达式 包裹这包括 3个类和1个接口 这个 JAVAutil。正则表达式 软件包主要由以下三类组成,如下表所示:
| 不。 | 类/接口 | 描述 |
|---|---|---|
| 1. | 模式类 | 用于定义模式 |
| 2. | 匹配类 | 用于使用模式对文本执行匹配操作 |
| 3. | 模式语法异常类 | 用于指示正则表达式模式中的语法错误 |
| 4. | 匹配结果接口 | 用于表示匹配操作的结果 |
java中的正则表达式为我们提供了 下面列出了3个类和1个接口:
- 模式类
- 匹配类
- 模式语法异常类
- 匹配结果接口
从下面提供的图片中可以理解如下:
第一类:模式类
此类是正则表达式的汇编,可用于定义各种类型的模式,不提供公共构造函数。这可以通过调用compile()方法创建,该方法接受正则表达式作为第一个参数,从而在执行后返回一个模式。
| 不。 | 方法 | 描述 |
|---|---|---|
| 1. | 编译(字符串正则表达式) | 它用于将给定的正则表达式编译成模式。 |
| 2. | 编译(字符串正则表达式,int标志) | 它用于将给定的正则表达式编译成具有给定标志的模式。 |
| 3. | 旗帜() | 它用于返回此模式的匹配标志。 |
| 4. | 匹配器(字符序列输入) | 它用于创建匹配器,将给定的输入与此模式匹配。 |
| 5. | 匹配项(字符串正则表达式、字符序列输入) | 它用于编译给定的正则表达式,并尝试将给定的输入与之匹配。 |
| 6. | 模式() | 它用于返回从中编译此模式的正则表达式。 |
| 7. | 引号(字符串s) | 它用于返回指定字符串的文本模式字符串。 |
| 8. | 拆分(字符序列输入) | 它用于围绕此模式的匹配项拆分给定的输入序列。 |
| 9 | 拆分(字符序列输入,整数限制) | 它用于围绕此模式的匹配项拆分给定的输入序列。limit参数控制应用图案的次数。 |
| 10 | toString() | 它用于返回此模式的字符串表示形式。 |
例子: 模式类
JAVA
// Java Program Demonstrating Working of matches() Method // Pattern class // Importing Pattern class from java.util.regex package import java.util.regex.Pattern; // Main class class GFG { // Main driver method public static void main(String args[]) { // Following line prints "true" because the whole // text "geeksforgeeks" matches pattern // "geeksforge*ks" System.out.println(Pattern.matches( "geeksforge*ks" , "geeksforgeeks" )); // Following line prints "false" because the whole // text "geeksfor" doesn't match pattern "g*geeks*" System.out.println( Pattern.matches( "g*geeks*" , "geeksfor" )); } } |
truefalse
2类:匹配器类
该对象用于在java中对输入字符串执行匹配操作,从而解释前面解释的模式。这也没有定义公共构造函数。这可以通过在任何模式对象上调用matcher()来实现。
| 不。 | 方法 | 描述 |
|---|---|---|
| 1. | 查找() | 它主要用于搜索文本中多次出现的正则表达式。 |
| 2. | 查找(int start) | 它用于从给定索引开始搜索文本中出现的正则表达式。 |
| 3. | 开始() | 它用于获取使用find()方法找到的匹配项的开始索引。 |
| 4. | 结束() | 它用于获取使用find()方法找到的匹配项的结束索引。它返回最后一个匹配字符旁边的字符索引。 |
| 5. | groupCount() | 它用于查找匹配子序列的总数。 |
| 6. | 组() | 它用于查找匹配的子序列。 |
| 7. | 匹配项() | 它用于测试正则表达式是否与模式匹配。 |
注: T型。matches()检查整个文本是否与模式匹配。其他方法(如下所示)主要用于查找文本中多次出现的模式。
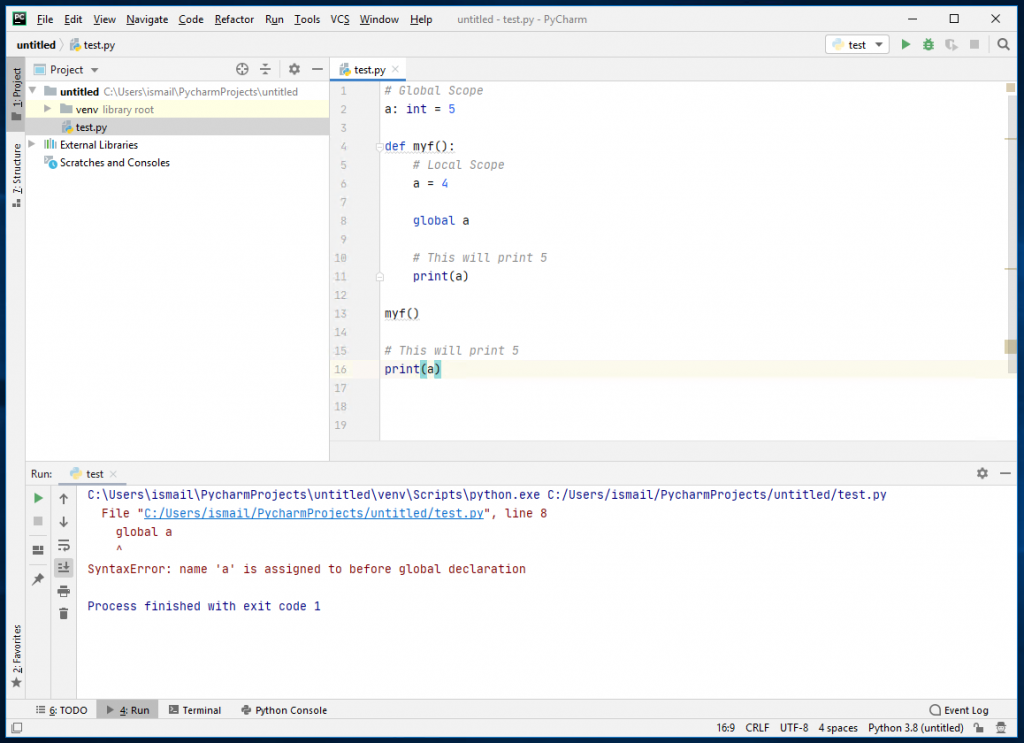
让我们像讨论Pattern类一样讨论几个示例程序。这里我们将讨论几个java程序,它们演示compile()、find()、start()、end()和split()的工作原理,以便更好地理解Matcher类。
例1: 模式搜索
JAVA
// Java program to demonstrate working of // String matching in Java // Importing Matcher and Pattern class import java.util.regex.Matcher; import java.util.regex.Pattern; // Main class class GFG { // Main driver method public static void main(String args[]) { // Create a pattern to be searched // Custom pattern Pattern pattern = Pattern.compile( "geeks" ); // Search above pattern in "geeksforgeeks.org" Matcher m = pattern.matcher( "geeksforgeeks.org" ); // Finding string using find() method while (m.find()) // Print starting and ending indexes // of the pattern in the text // using this functionality of this class System.out.println( "Pattern found from " + m.start() + " to " + (m.end() - 1 )); } } |
Pattern found from 0 to 4Pattern found from 8 to 12
例2: 简单正则表达式搜索
JAVA
// Java program to demonstrate working of // String matching in Java // Importing Matcher and Pattern class // from java.util package import java.util.regex.Matcher; import java.util.regex.Pattern; // Main class class GFG { // Main driver method public static void main(String args[]) { // Creating a pattern to be searched // Custom pattern to be searched Pattern pattern = Pattern.compile( "ge*" ); // Searching for the above pattern in // "geeksforgeeks.org" Matcher m = pattern.matcher( "geeksforgeeks.org" ); // Checking whether the pattern is there or not // using find() method while (m.find()) // Print starting and ending indexes of the // pattern in text using method functionality of // this class System.out.println( "Pattern found from " + m.start() + " to " + (m.end() - 1 )); } } |
Pattern found from 0 to 2Pattern found from 8 to 10Pattern found from 16 to 16
例3: 不区分大小写的模式搜索
JAVA
// Java Program Demonstrating Working of String matching // Importing Matcher class and Pattern classes // from java.util.regex package import java.util.regex.Matcher; import java.util.regex.Pattern; // Main class class GFG { // Main driver method public static void main(String args[]) { // Creating a pattern to be searched Pattern pattern = Pattern.compile( "ge*" , Pattern.CASE_INSENSITIVE); // Searching above pattern in "geeksforgeeks.org" Matcher m = pattern.matcher( "GeeksforGeeks.org" ); // Find th above string using find() method while (m.find()) // Printing the starting and ending indexes of // the pattern in text using class method // functionalities System.out.println( "Pattern found from " + m.start() + " to " + (m.end() - 1 )); } } |
Pattern found from 0 to 2Pattern found from 8 to 10Pattern found from 16 to 16
例4: split()方法 根据分隔符模式拆分文本。
string split()方法在给定正则表达式的匹配项周围打断给定字符串。这个方法有两种变体,所以在开始实现这个方法之前,一定要仔细研究一下。
插图:
Input --> String: 016-78967Output --> Regex: {"016", "78967"}
JAVA
// Java program Illustrating Working of split() Method // by Splitting a text by a given pattern // Importing Matcher and Pattern classes from // java.util.regex package import java.util.regex.Matcher; import java.util.regex.Pattern; // Main class class GFG { // Main driver method public static void main(String args[]) { // Custom string String text = "geeks1for2geeks3" ; // Specifies the string pattern // which is to be searched String delimiter = "\d" ; Pattern pattern = Pattern.compile( delimiter, Pattern.CASE_INSENSITIVE); // Used to perform case insensitive search of the // string String[] result = pattern.split(text); // Iterating using for each loop for (String temp : result) System.out.println(temp); } } |
geeksforgeeks
现在我们已经结束了对这两门课的讨论。现在,我们将向您介绍两个新概念,这两个概念非常明确,而且还有一个与
类别3:PatternSyntaxException类别
这是Regex的一个对象,用于指示正则表达式模式中的语法错误,是一个 未检查的异常 以下是PatternSyntaxException类中的方法,如下表所示。
| 不。 | 方法 | 描述 |
|---|---|---|
| 1. | getDescription() | 它用于检索错误的描述。 |
| 2. | getIndex() | 它用于检索错误索引。 |
| 3. | getMessage() | 它用于返回一个多行字符串,其中包含语法错误及其索引的描述、错误的正则表达式模式,以及模式中错误索引的视觉指示。 |
| 4. | getPattern() | 它用于检索错误的正则表达式模式。 |
接口1:匹配结果接口
此接口用于确定正则表达式的匹配操作的结果。必须注意的是,尽管可以看到匹配边界、组和组边界,但不允许通过匹配结果进行修改。以下是本界面中的方法,如下表所示:
| 不。 | 方法 | 描述 |
|---|---|---|
| 1. | 结束() | 它用于在匹配最后一个字符后返回偏移量。 |
| 2. | 完(国际组) | 它用于返回给定组在此匹配过程中捕获的子序列的最后一个字符后的偏移量。 |
| 3. | 组() | 它用于返回与上一个匹配匹配的输入子序列。 |
| 4. | 组(int组) | 它用于返回给定组在上一次匹配操作中捕获的输入子序列。 |
| 5. | groupCount() | 它用于返回此匹配结果模式中的捕获组数。 |
| 6. | 开始() | 它用于返回匹配的开始索引。 |
| 7. | 开始(int组) | 它用于返回给定组在此匹配期间捕获的子序列的开始索引。 |
最后,让我们讨论一下从上述文章中检索到的一些重要观察结果
- 我们通过调用pattern来创建一个pattern对象。compile(),没有构造函数。compile()是模式类中的静态方法。
- 与上面一样,我们在Pattern类的对象上使用Matcher()创建Matcher对象。
- 图案matches()也是一个静态方法,用于检查给定文本作为一个整体是否与模式匹配。
- find()用于查找文本中多次出现的模式。
- 我们可以使用split()方法基于分隔符模式分割文本
本文由 阿卡什奥哈 .如果你喜欢GeekSforgek,并想贡献自己的力量,你也可以写一篇文章,然后将文章邮寄给评论-team@geeksforgeeks.orgerror-索引。看到你的文章出现在Geeksforgeks主页上,并帮助其他极客。如果您发现任何不正确的地方,或者您想分享有关上述主题的更多信息,请写下评论。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)