给定一个单词,找出它在词典中更大的排列。例如,在词典学上,“gfg”的下一个排列是“ggf”,而“acb”的下一个排列是“bac”。
注意:在某些情况下,下一个按字典顺序排列的较大单词可能不存在,例如,“aaa”和“edcba”
在C++中,有一个特殊的功能,可以节省大量代码。它在文件#include
让我们看看下面的代码片段:
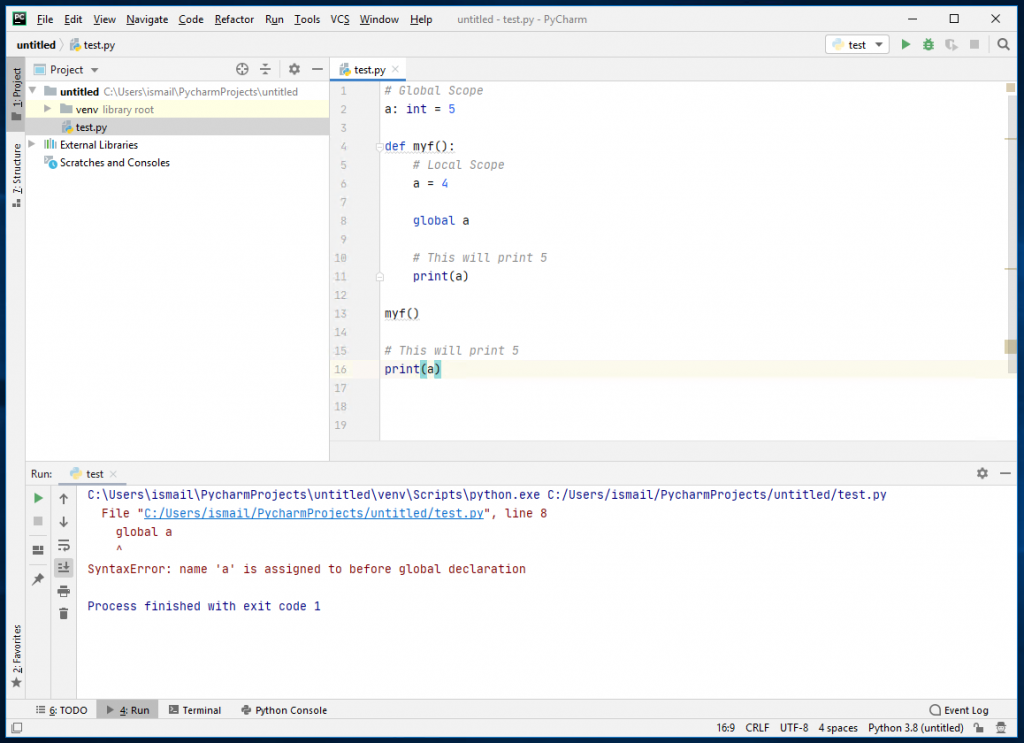
// Find the next lexicographically // greater permutation of a word #include <algorithm> #include <iostream> using namespace std; int main() { string s = { "gfg" }; bool val = next_permutation(s.begin(), s.end()); if (val == false ) cout << "No Word Possible" << endl; else cout << s << endl; return 0; } |
ggf
同样的程序也可以 不使用STL实现 .下面是同样的代码片段。这个想法基于以下事实: 1) 按降序排序的序列没有下一个排列。例如,edcba“没有下一个排列。 2) 对于未按降序排序的序列,例如“abedc”,我们可以遵循以下步骤。 ……….a) 从右侧遍历,找到第一个不按降序排列的项。例如,在“abedc”中,字符“b”不遵循降序。 ……….b) 将找到的字符与其右侧最近的较大(或最小较大)元素交换。对于“abedc”,我们用“c”作为最接近的大元素。在交换“b”和“c”之后,字符串变成“acedb”。 ……….c) 交换后,根据步骤中找到的字符位置对字符串进行排序 A. .对“acedb”的子字符串“edb”进行排序后,我们得到“ 溴化二苯醚 “这是所需的下一个排列。
步骤b)和c)中的优化 a) 由于序列是按降序排序的,所以我们可以使用二进制搜索来查找最近的较大元素。 c) 由于序列已经按降序排序(即使在我们用最接近的较大值进行交换之后),我们可以在反转序列后按升序排序。
// Find the next lexicographically // greater permutation of a word #include <iostream> using namespace std; void swap( char * a, char * b) { if (*a == *b) return ; *a ^= *b; *b ^= *a; *a ^= *b; } void rev(string& s, int l, int r) { while (l < r) swap(&s[l++], &s[r--]); } int bsearch (string& s, int l, int r, int key) { int index = -1; while (l <= r) { int mid = l + (r - l) / 2; if (s[mid] <= key) r = mid - 1; else { l = mid + 1; if (index == -1 || s[index] >= s[mid]) index = mid; } } return index; } bool nextpermutation(string& s) { int len = s.length(), i = len - 2; while (i >= 0 && s[i] >= s[i + 1]) --i; if (i < 0) return false ; else { int index = bsearch (s, i + 1, len - 1, s[i]); swap(&s[i], &s[index]); rev(s, i + 1, len - 1); return true ; } } // Driver code int main() { string s = { "gfg" }; bool val = nextpermutation(s); if (val == false ) cout << "No Word Possible" << endl; else cout << s << endl; return 0; } // This code is contributed by Mysterious Mind |
ggf
时间复杂性:
- 在最坏的情况下,下一次排列的第一步需要O(n)时间。
- 二进制搜索需要O(logn)时间。
- 反转需要O(n)时间。
总体时间复杂度为O(n)。 其中n是字符串的长度。
参考: http://www.cplusplus.com/reference/algorithm/next_permutation/
本文由 哈希特·古普塔 .如果你喜欢GeekSforgek,并且想贡献自己的力量,你也可以写一篇文章,并将文章邮寄到contribute@geeksforgeeks.org.看到你的文章出现在Geeksforgeks主页上,并帮助其他极客。
如果您发现任何不正确的地方,或者您想分享有关上述主题的更多信息,请写下评论。

![关于”PostgreSQL错误:关系[表]不存在“问题的原因和解决方案-yiteyi-C++库](https://www.yiteyi.com/wp-content/themes/zibll/img/thumbnail.svg)